Did we undercount Medicaid numbers? Four examples of data limitation.
By Emily Campbell / March 20, 2023
The Ohio Legislative District Fact Sheets are the most comprehensive and reliable collection of data points on conditions facing people in each Ohio Senate and Ohio House district in the state that we are able to produce. Still, every statistic carries some level of uncertainty and these Fact Sheets are no exception.
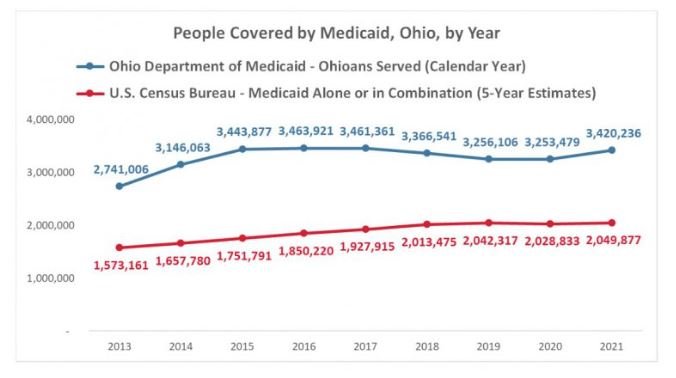
The Ohio Department of Medicaid dashboard Who We Served – Annual Timeline shows over 3.4 million Ohioans served by Medicaid in 2021. This is a significantly higher number than the 2.1 million Ohioans listed on our State of Ohio Legislative Fact Sheet. How can the gap be so large? Several factors contribute to what we believe is an undercount in Medicaid figures included in our Fact Sheet. Even though we know there are probably many more Ohioans enrolled in Medicaid, these remain the best estimates for the time and the geography.
In order to be able to produce consistent information for all 132 Ohio General Assembly Districts, we had to use the U.S. Census Bureau’s American Community Survey 2017-2021 five-year estimates. There is simply no other source that provides reliable figures on a variety of topics for these small geographies. There are several aspects of this data source that contribute to the seemingly low number of Ohioans who are reported to have Medicaid health coverage.
Administrative data is the most accurate
We strongly suggest that advocates and policymakers trust the numbers which are provided by the Ohio Department of Medicaid. They are in the best position to know the TRUE number of Ohioans enrolled in the programs they administer. Agencies have some information on every single person who is enrolled in their programs. This makes administrative data incredibly accurate, if you can get it. Although great strides have been made toward open data, sometimes data is trapped inside agencies. It may be difficult to get out of program databases in a usable format. It is usually subject to confidentiality protections which limit what agencies can share. Even so, for straight caseload data, it’s the unquestioned best.
Administrative data is a byproduct of the work of agencies, not something created for research purposes. There is some information that agencies simply don’t collect. For example: the SNAP application does not include a question about race or ethnicity, so data from the Ohio Department of Job and Family Services about enrollees can’t tell us the racial makeup of who receives SNAP in Ohio.
On the other hand, data from the U.S. Census Bureau is collected exclusively to provide information about people and communities. It is provided on a consistent basis in a useable format which allows for analysis by small geography (like legislative district) and for various population groups. But it also has limitations. The American Community Survey (ACS) on which Community Solutions often relies is collected via survey (as the name suggests). The complex process to turn survey responses into counts for whole communities has some uncertainty, expressed as margins of error. It’s also self-reported, which introduces questions that we’ll explore in more depth below.
Timeframes may not line up
While Ohio Department of Medicaid can provide an up-to-the-minute number of people enrolled in their programs, there’s always a delay of about a year in the release of the ACS data.
The data on which our Legislative Fact Sheets is built is the latest available, but it is from the ACS five-year estimates from 2017-2021. For smaller geographies, the Census Bureau groups several years of surveys together to produce an estimate of what the number is today. This makes the data they report much more reliable but dampens year-over-year changes. For example, there was a large jump in the number of Ohioans who received Medicaid when Medicaid Expansion went into full effect in 2014 (below), which is reflected in the data from the Department of Medicaid, but not as much in the ACS 5-year estimates.
People may not say they have Medicaid (or may not know!)
The precise wording of a question or way information is collected can influence what a data point expresses. Self-reported data isn’t inherently bad, but it does introduce the possibility of human error from the very beginning as different people may interpret questions differently. The ACS questions are routinely tested to reduce the chance of misinterpretation or response bias, but they can never be completely eliminated because people aren’t perfect. Below is the actual health insurance question as it appears on the ACS questionnaire.

Immediately we see that the question asks about CURRENT coverage. Medicaid’s annual report indicates the total number of Ohioans served, which could be more than those on the program at any given time.
People often mix up MedicAID and MediCARE, which is probably why the ACS questionnaire describes the two programs in their question. We also wonder if everyone who is on Medicaid realizes that’s where their coverage is coming from. According to Ohio Department of Medicaid, 90 percent of Ohioans receive coverage through a Managed Care Organization, including AmeriHealthCaritas, Anthem, Buckeye, CareSource, Humana, Molina, and UnitedHealthcare. These company names may be more familiar to the average Ohioan than “Medicaid.”
On surveys Community Solutions conducted, we began to notice that people were indicating “Other” as their health insurance and writing down CareSource or another MCO. We suspect the same thing happens in the ACS.
We never mess with the source
It’s very rare that we are able to get all the data we hope to see reported exactly as we would like to use it. We are limited to what data is available. When the health insurance data is reported in ACS (Table B27010), they list out types of coverage alone as well as the most common combinations, including Medicare and Medicaid coverage together. But there are a substantial number of people who have “Other coverage combinations.” We can’t be sure if Medicaid is part of the mix or not, so rather than guessing, we leave those individuals out of the Medicaid count.
If we know that the Medicaid numbers on our Legislative District Fact Sheets are almost certainly too low, why don’t we adjust them?
Good data sources have clearly outlined methodology, allowing someone using the data to understand the limitations and decide how best to use the data. Any adjustments that we make introduce even more uncertainty as they require researchers to make additional assumptions. For example: without deep analysis we don’t know whether the Medicaid undercount is evenly distributed across the state or if it impacts higher and lower-income areas differently.
The statisticians and data scientists at the Census Bureau carefully test any adjustment to ensure they aren’t introducing undue data bias into the statistics they report. We trust them.
So, why do we bother to include such a flawed number?
Policymakers, advocates, and community members are hungry for information they can use to try to understand conditions in their communities. Community Solutions works hard to provide data that meets our standards and can be useful and used to advance conversations about pressing issues facing Ohioans. Otherwise, we’re all just guessing.